Аналитик данных работает с информацией из множества разных источников. Чтобы анализировать разнородную информацию, нужен ETL-процесс. Рассказываем, в чём суть, и как его настроить.

ETL — это процесс транспортировки данных, при котором информацию из разных мест преобразуют и кладут в новое место. ETL расшифровывается как extract, transform, load, то есть «извлечь, трансформировать, загрузить».
Обычно данные компании хранятся в разных местах:
● файлы на рабочих компьютерах;
● Google-таблицы;
● почта;
● облачный сервер;
● базы данных;
● копии баз данных, которые используют для отчётности;
● CRM (система взаимодействия с клиентами);
● внешние и внутренние API.
У каждого источника свой способ предоставления доступа к данным: к базам данных надо подключиться напрямую, к файлам надо получить ссылки, к API — токен авторизации. Часто эти способы недоступны для быстрого использования, поэтому сравнивать данные из разных источников сложно. Чтобы с данными было удобно работать, им надо придать единую структуру, убрать лишнее и положить в хранилище данных. Для этого и нужен ETL-процесс.

Без ETL-процессов данные из разных источников приходилось бы собирать и переписывать вручную
Кто и где использует ETL
ETL-процессы используют аналитики и инженеры данных в IT-компаниях, которые сталкиваются с одной из двух проблем:
● Данных стало слишком много, поэтому аналитические запросы работают долго, а за хранение лишних данных приходится платить.
● Данные лежат в разных местах, поэтому аналитики не могут с ними работать.
Рассмотрим оба случая подробно.
Данных слишком много
Допустим, компания «Альфа» хранит информацию в базе данных класса OLTP (англ. Online Transaction Processing). Она рассчитана на быструю запись и чтение одной единицы данных — строчки.
Когда аналитики работают с данными компании, они делают запросы к этой базе. Например, чтобы узнать, сколько пользователей посетило сайт «Альфы» за вчерашний день, надо перебрать все строки в базе за этот день. Чем больше становится пользователей, тем больше вычислительных мощностей нужно, чтобы перебрать все строки. В какой-то момент появляются проблемы: запросы начинают работать долго или вовсе перестают из-за ограничений базы данных — в ответ на запрос база данных просто возвращает ошибку.

В OLTP-базах перебираются все данные в строчке. Если нужна информация из одной колонки, то анализировать придётся все три
Чтобы упростить обработку таких запросов, придумали класс аналитических систем OLAP (англ. Online Analytical Processing). Такие базы данных называют «колоночными» — они раскладывают информацию по отдельным колонкам, где у каждой своё свойство. Чтобы посмотреть дату посещения сайта, достаточно проанализировать одну колонку с нужным свойством и не перебирать все данные в каждой строке. Благодаря этому расчёты становятся быстрее.
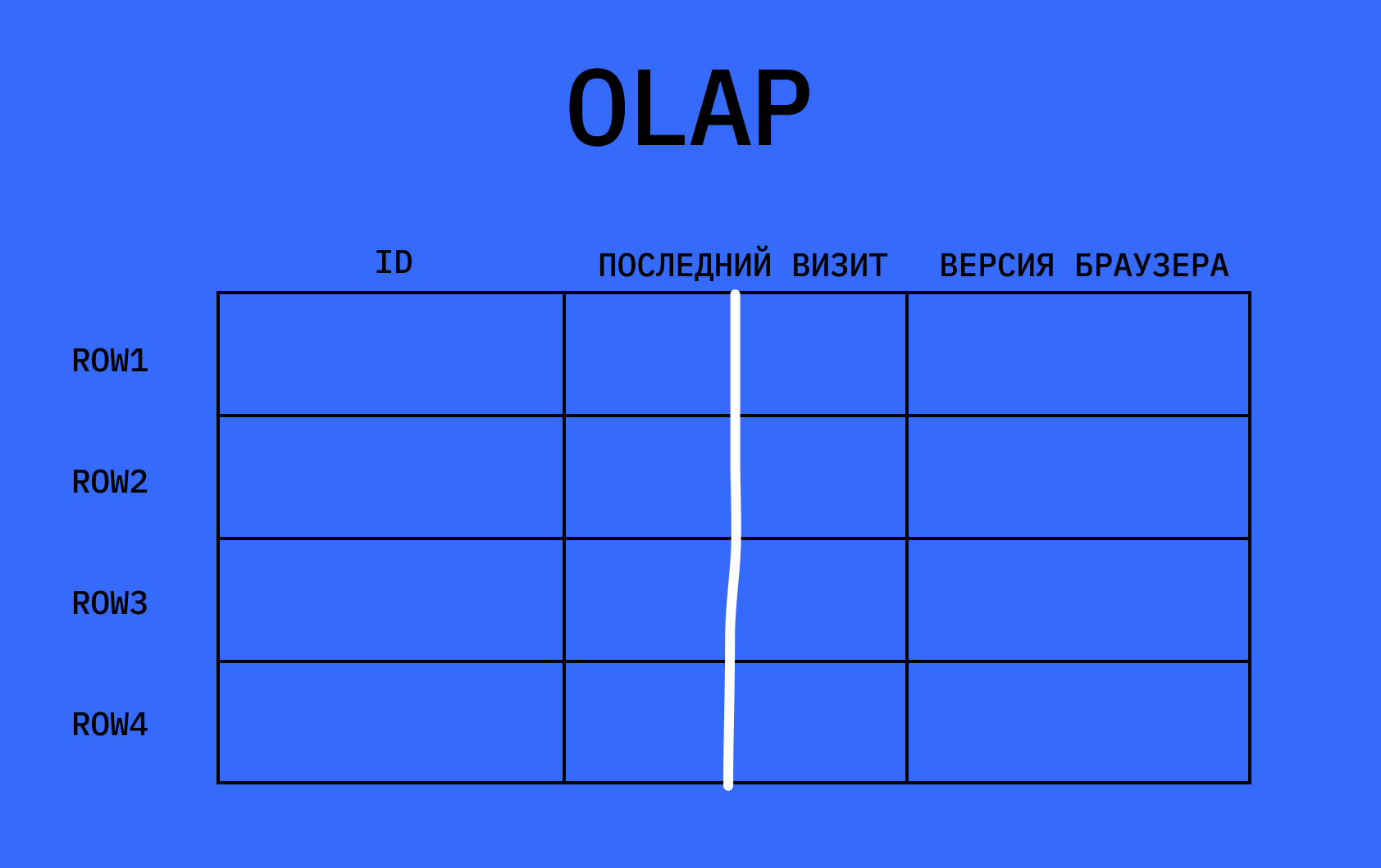
В OLAP-базах перебираются только данные из нужной колонки
Рассчитать количество посетителей, средний чек или медиану по возрасту — всё это аналитические функции. Чтобы переместить данные в базу, предназначенную для аналитических процессов, используют ETL.
Данные лежат в разных местах
Например, в 2007 году дизайнер Антон сделал аккаунт на Яндекс Почте, придумал ник, добавил туда дату рождения и указал гендер. Эта информация хранится в одной базе, которую делала команда разработчиков Яндекс Почты.
В 2022 году Антон решил попробовать себя в аналитике данных и вошёл в Практикум со своего аккаунта Яндекса. Антон проходит вводный курс, а информация о его прогрессе попадает в новую базу данных.
Маркетолог Практикума приходит к аналитику и спрашивает: «Как возраст студентов влияет на проходимость пробного курса?» Аналитик не может ответить, потому что данные о возрасте лежат в одной базе из 2007 года, а данные о прохождении курса — в другой. Чтобы решить задачу, аналитик соединяет данные из разных систем и сохраняет их в аналитическом хранилище. Теперь данные об учениках Практикума лежат в одном месте, и их удобно анализировать.
Вот ещё несколько примеров задач, в которых ETL помогает объединить данные из разных источников:
- Аналитики сервиса доставки еды хотят узнать, как персональные рекомендации товаров влияют на продажи. Рекомендации — это одна база данных, а корзина — другая. Чтобы сравнить данные из двух систем, настраивают ETL-процесс.
- Банк выдаёт кредиты. В одной системе лежит информация о денежных переводах, а в другой системе — статус заявки на кредит. ETL связывает данные о платежах по кредитам с данными анкеты. Эту информацию используют аналитики, чтобы понимать, какие факторы в анкете влияют на исполнение обязательств по кредиту.
- Разработчики сервиса онлайн-платежей хотят сделать удобную сортировку методов оплаты для геймеров. Для этого надо сопоставить жанр игры, регион и платёжную систему, которой пользуются чаще всего. Данные о жанрах хранятся в одном месте, а транзакции — в другом. Настроив ETL-процесс, можно сразу предлагать любителям Warcraft из Петербурга — QIWI, а тамбовским игрокам в World of Tanks — Robokassa.
ETL-процессы помогают компании внедрять полезные функции и принимать стратегические решения. На курсе «Инженер данных с нуля» студенты учатся пользоваться ETL-инструментами и внедрять процессы в работу.
Научитесь разрабатывать архитектуру данных с нуля
Получите знания по созданию и обслуживанию инфраструктуры для работы с данными, даже если никогда раньше не работали с ними. После обучения в вашем портфолио будет 9+ проектов.

Преимущества и недостатки ETL
В ходе преобразования в ETL-процессе часть данных может потеряться. Когда риск потерять данные слишком высок, используют ELT-процесс — он расшифровывается как extract, load, transform. Данные сначала перекладывают из нескольких мест в одно хранилище, а потом уже приводят в порядок.
Когда в компании появляется задача объединить множество данных в одном месте, используют оба процесса.
Материал по теме:
Что такое машинное обучение

Как работает ETL-процесс
Хотя аббревиатура ETL содержит всего три этапа обработки данных, на практике процесс можно разделить на шесть шагов:
1. Подключение к источнику
Первым делом нужно подключиться к системе, из которой будут выгружать данные. Это делают с помощью специальных приложений, например Apache Airflow. Для работы автоматизированных процессов нужно создать отдельную учётную запись с ограниченными правами. Такая учётная запись называется сервисной.
2. Выгрузка данных из источника
Если источником выступает база данных, то для получения информации отправляют SQL-запрос — это набор команд для работы с табличными базами данных. Если данные надо получить из внешнего источника, например CRM, файлов или почты, то обращаются к API, который позволяет разным приложениям обмениваться данными между собой.
На этом этапе важно учитывать объём выгружаемых данных: если в системе, которая принимает данные, не хватит памяти, процессы будут работать с ошибками.
3. Первичная очистка данных
Иногда данные надо очищать от тестовой информации или дублей. Инженер данных предусматривает возможные ошибки и прописывает правила в SQL-запросах.
4. Маппинг данных
В компании могут использовать несколько разных источников, не связанных между собой. Чтобы данные из разных источников собрать в одной таблице, надо задать каждому свойству новое название — это и есть маппинг (от англ. mapping). Допустим, аналитик выгружает из базы идентификатор клиента, а из CRM — даты его заказов. Тогда в итоговом хранилище должны появиться колонки с названиями client_id и order_date.
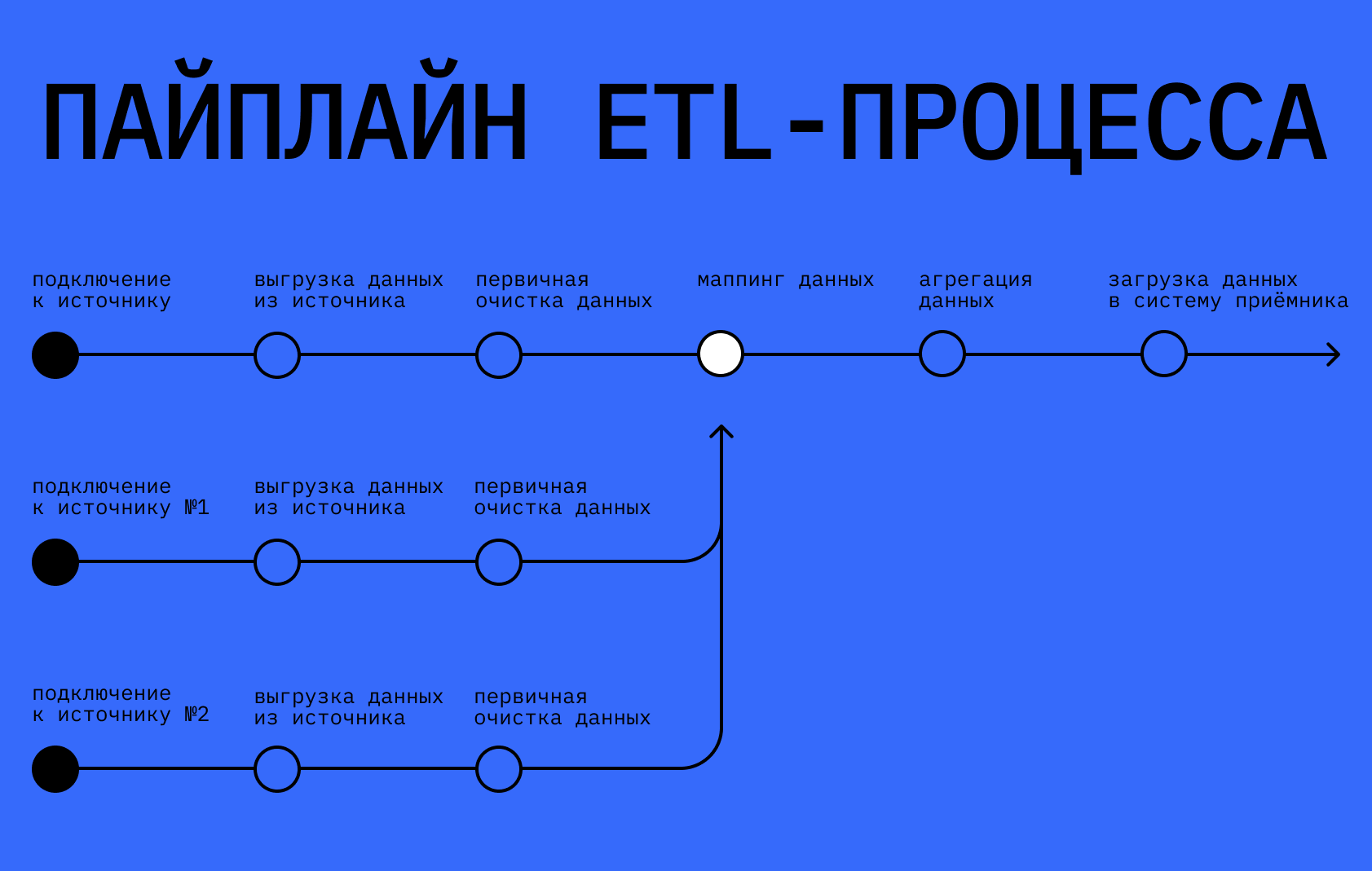
При маппинге все данные связываются между собой
- Агрегация данных
Агрегация — это соединение данных в итоговой таблице. Допустим, нужно узнать, сколько в среднем заказов делают клиенты разных возрастов.
Таблица с заказами:
order_id | client_id | order_date |
|---|---|---|
1 | 4 | 2021-10-01 |
2 | 6 | 2021-10-02 |
Таблица с клиентами:
client_id | client | age |
|---|---|---|
4 | Mark | 23 |
6 | Inna | 35 |
На этапе маппинга таблицы связали по полю client_id. При агрегации получится расчёт нужных данных:
age | orders | count |
|---|---|---|
23 | 13 | |
35 | 15 |
- Загрузка данных в систему-приёмник
Если система-приёмник — это база, то данные загружаются в таблицы. Если же аналитик работает с API, файловым хранилищем или другими сервисами, то загрузка должна проходить по заданным правилам.
Как реализовать ETL-процесс
Чтобы настроить ETL-процесс, аналитику нужно совершить пять шагов:
1. Понять задачу
Например, в компании разрабатывают систему бонусов для продавцов. Для этого нужно проанализировать данные об объёмах продаж и бонусах. Инженеру данных ставят задачу настроить процесс сбора и поставки данных в аналитическое хранилище. Для этого инженер должен узнать:
- Какие системы используются для хранения данных: CRM, базы данных, документы.
- Как должна выглядеть таблица-приёмник, в которую будут сохранять итоговую информацию: какой должен быть формат и названия колонок.
- Как часто информацию необходимо обновлять: раз в день, раз в час или в режиме реального времени.
- Какую информацию надо обновлять: только ту, что появилась за установленное время, или ту, что уже была в базе.
- Какие могут быть проблемы в данных и как их обработать. Например, пропуски, аномалии, тестовые значения, некорректные форматы.
- Как система будет уведомлять заказчика о возникших проблемах. Например, если в один день в систему поступит в два раза меньше данных, чем обычно.
После понимания задачи инженер запрашивает доступ к данным.
2. Получить доступ к данным
К примеру, данные о продажах хранятся в 1С, данные о сотрудниках — в Google-таблицах, а бонусы — в базе данных. У систем разные требования к доступу и ответственные, которые могут этот доступ предоставить. Чтобы получить доступ к данным, обычно делают следующее:
- Обращаются к ответственным и согласуют у них доступ к системам и нужным данным.
- Создают отдельную учётную запись для работы автоматического процесса ETL. Это нужно, чтобы контролировать, кто забирает эти данные.
- Создают персональную учётную запись инженера данных для быстрой проверки данных и отладочных работ. Обычно дают ограниченный доступ, например, чтобы инженер не видел персональных данных клиентов.
- Дают доступ к тестовому контуру — тестовым данным, на которых можно настроить и протестировать ETL-процесс.
3. Проверить полученные данные
На этом этапе нужно разобраться, какие данные понадобятся, а какие придётся отсеять. Например, в таблицах могут быть тестовые аккаунты продавцов, которые не надо учитывать. Или бонусы могут начисляться в копейках, а в хранилище данных они должны попасть в рублях. Инженер данных получает часть информации, анализирует её и, если видит, что данные надо предобработать, учитывает это при написании кода. Эту часть обработки ещё называют «препроцессинг данных».
4. Написать код ETL-процесса
После того как станет понятно, какие нужны данные, откуда их брать и как обрабатывать, инженер данных пишет код, который потом становится ETL-пайплайном (англ. ETL pipeline) — так аналитики называют ETL-процесс. При написании кода происходит его тестирование:
- Код технически работает исправно, не выдаёт ошибок при исполнении.
- Код написан читаемо: корректны названия параметров, переносы строк и табуляция, правила форматирования текста.
- Данные обрабатываются корректно, после их обработки нет ошибок в расчётах.
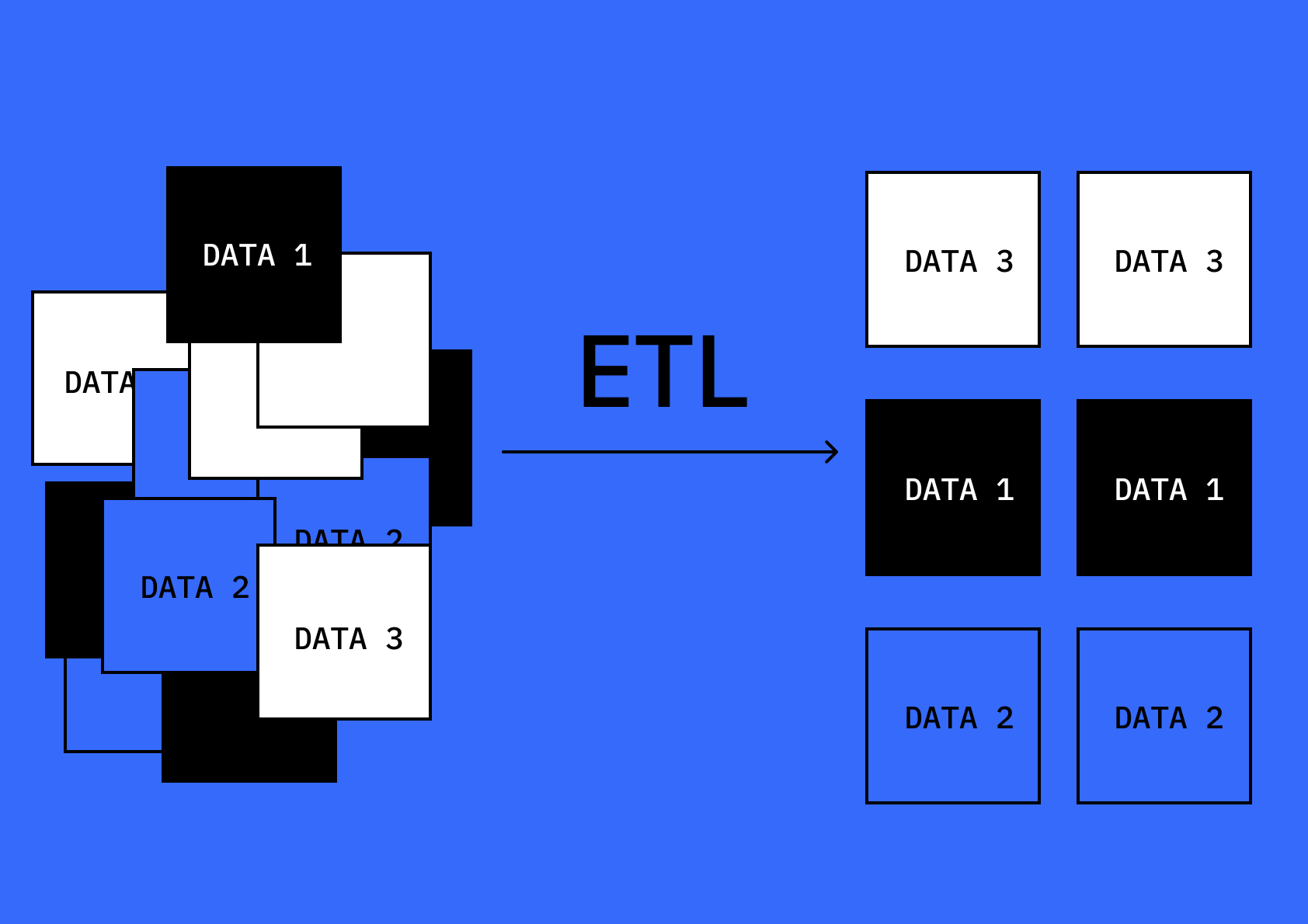
Аналитик задает новую структуру хранения данных, а ETL-процесс раскладывает данных из старых источников по нужным ячейкам таблицы
Далее остаётся автоматизировать всё ETL-решение и передать заказчикам.
5. Запустить автоматическое исполнение кода
Чтобы не запускать ETL-процесс каждый раз вручную, есть специальные инструменты, например Apache Airflow или PySpark. Это фреймворки, которые выполняют подготовленный код, а за выполнением задач можно наблюдать в интерфейсе и логах.
ETL-пайплайн можно описать как набор последовательно выполняемых задач на примере батчевого процесса в Apache Airflow. Батчевый процесс значит, что данные берут «порциями» и запускают процесс по расписанию.

Последовательный ETL-процесс
При работе на распределённых системах ETL-процесс может быть спроектирован так, что задачи будут выполняться параллельно.
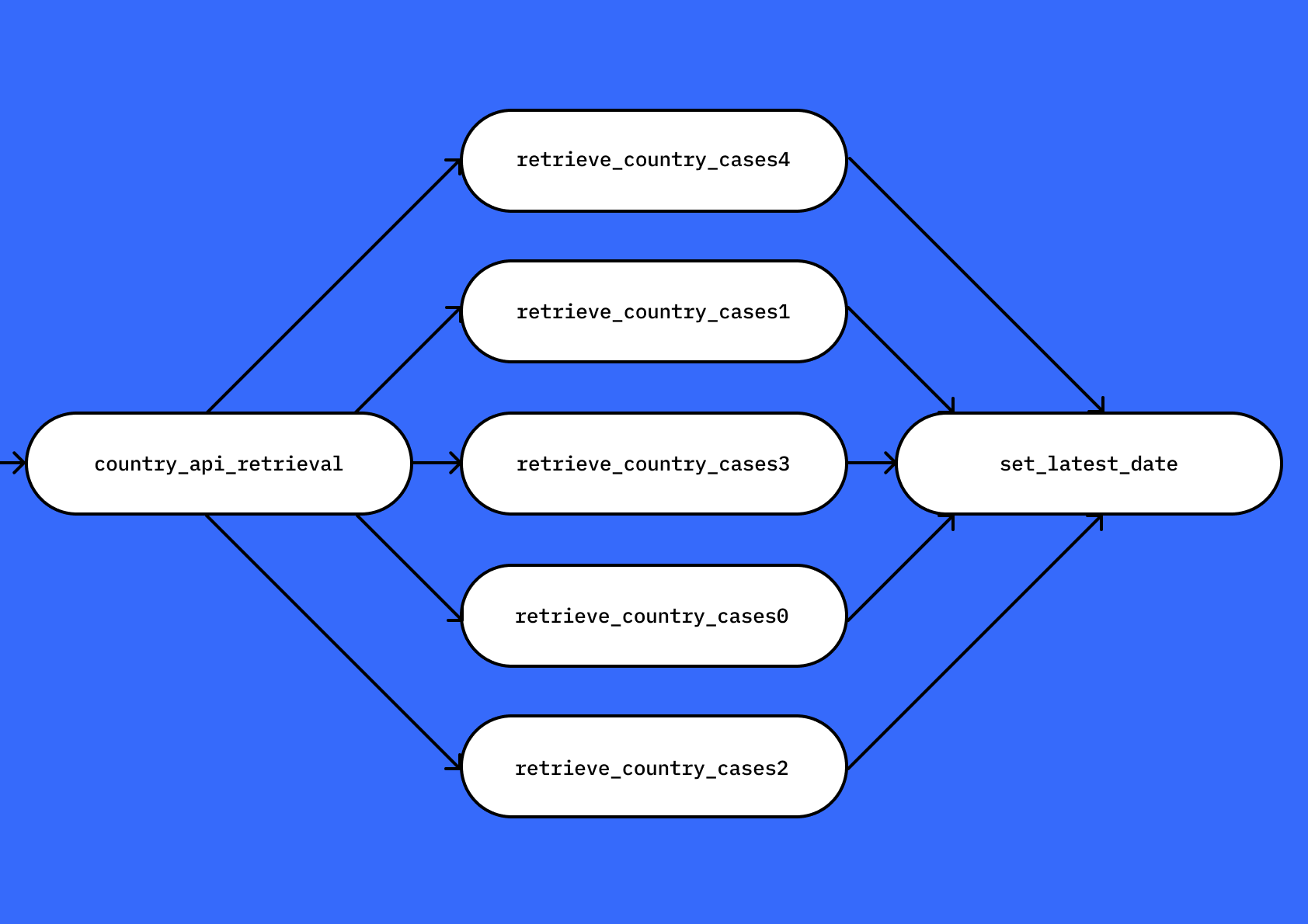
Параллельный ETL-процесс
Код можно выполнять в режиме реального времени или по расписанию: например, каждый день в 10 утра обрабатывать данные за вчерашний день.
Примеры ETL‑систем
Apache Airflow
Одна из самых популярных систем для управления ETL-процессами. Запускает задачи:
- по триггеру,
- по расписанию,
- по сенсору.
Есть интерфейс работы с аудитом процессов и мониторингом решений. Позволяет запускать десятки и тысячи ETL-процессов одновременно: например, чтобы собирать статистику продаж по франшизным ресторанам из разных городов.
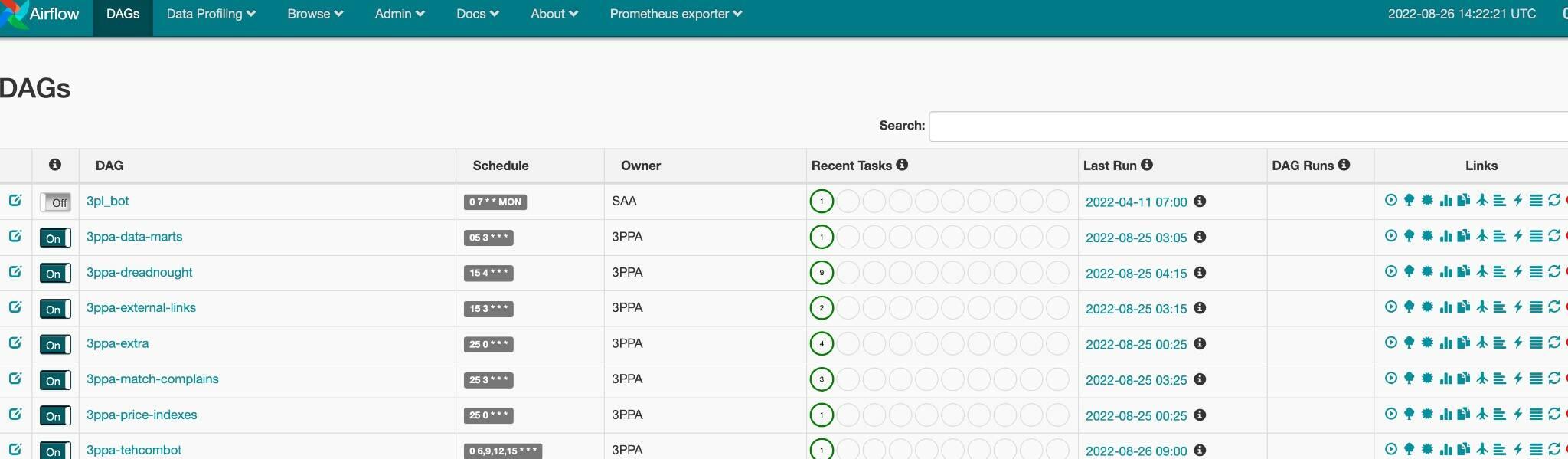
Интерфейс Apache Airflow
PySpark
PySpark — фреймворк, с помощью которого строятся приложения для распределённой обработки данных. Его главная особенность в том, что Spark хранит и обрабатывает данные в оперативной памяти, а не в файловой системе. PySpark полезен для задач, когда необходимо производить быстрые вычисления над большим объёмом данных: например, обрабатывать сообщения в соцсети с аудиторией 25 миллионов пользователей.
Совет эксперта
Дайджест блога: ежемесячная подборка лучших статей от редакции


Читать также:



