Чтобы анализировать большие данные, нужно писать программы и скрипты. Для этого можно использовать многие языки программирования, но некоторые подходят лучше — содержат много готовых инструментов, функций и библиотек для эффективной обработки данных.

1. Python

Самый популярный язык программирования в рейтинге TIOBE. Его используют для разных целей: веб-разработки, программирования умных устройств, разработки API. Но особой популярностью Python пользуется у тех, кто работает с большими данными. С его помощью:
● пишут искусственный интеллект и программы для машинного обучения;
● обрабатывают большие данные с помощью готовых библиотек и фреймворков;
● извлекают и собирают данные из разрозненных источников;
● визуализируют результаты анализа данных.
Для Python существуют специализированные библиотеки для работы с большими данными: NumPy для вычислений, pandas для анализа табличных данных, Matplotlib и Seaborn для визуализации, Scrapy для поиска данных.
Это только некоторая часть из обширного зоопарка библиотек, доступного на Python
На курсе Яндекс Практикума «Аналитик данных» студентов учат именно языку Python: рассказывают, как в нём работать с типами данных, применять библиотеки и проводить классический и статистический анализ данных.




2. R

Один из самых старых языков для анализа данных и работы со статистикой: сбора данных в таблицы, их очистки, проведения статистических тестов и составления графических отчётов. Его активно используют для научных исследований в любых сферах — например, в маркетинге, — а также для машинного обучения и статистического анализа данных.
Чтобы работать с R, желательно знать матанализ, теорию вероятностей и статистические методы. Поэтому его чаще используют именно в науке, а ещё он считается одним из основных языков программирования для Data Science.
Для R существуют тысячи библиотек и расширений для визуализации данных, быстрых статистических операций, распознавания текстов, A/B-тестирования и отдельных научных отраслей.
Материал по теме:
Язык программирования R: что делает его таким важным для анализа данных
3. Java

Как и Python, это универсальный язык: на нём работают с большими данными и создают ПО и приложения. Один из его главных плюсов — кроссплатформенность. Написанный на Java код работает на ПК, смартфонах, консолях, серверах и датчиках умного дома. Это происходит благодаря тому, что код Java запускается на специальной виртуальной машине, поддержка которой есть у большинства современных устройств.
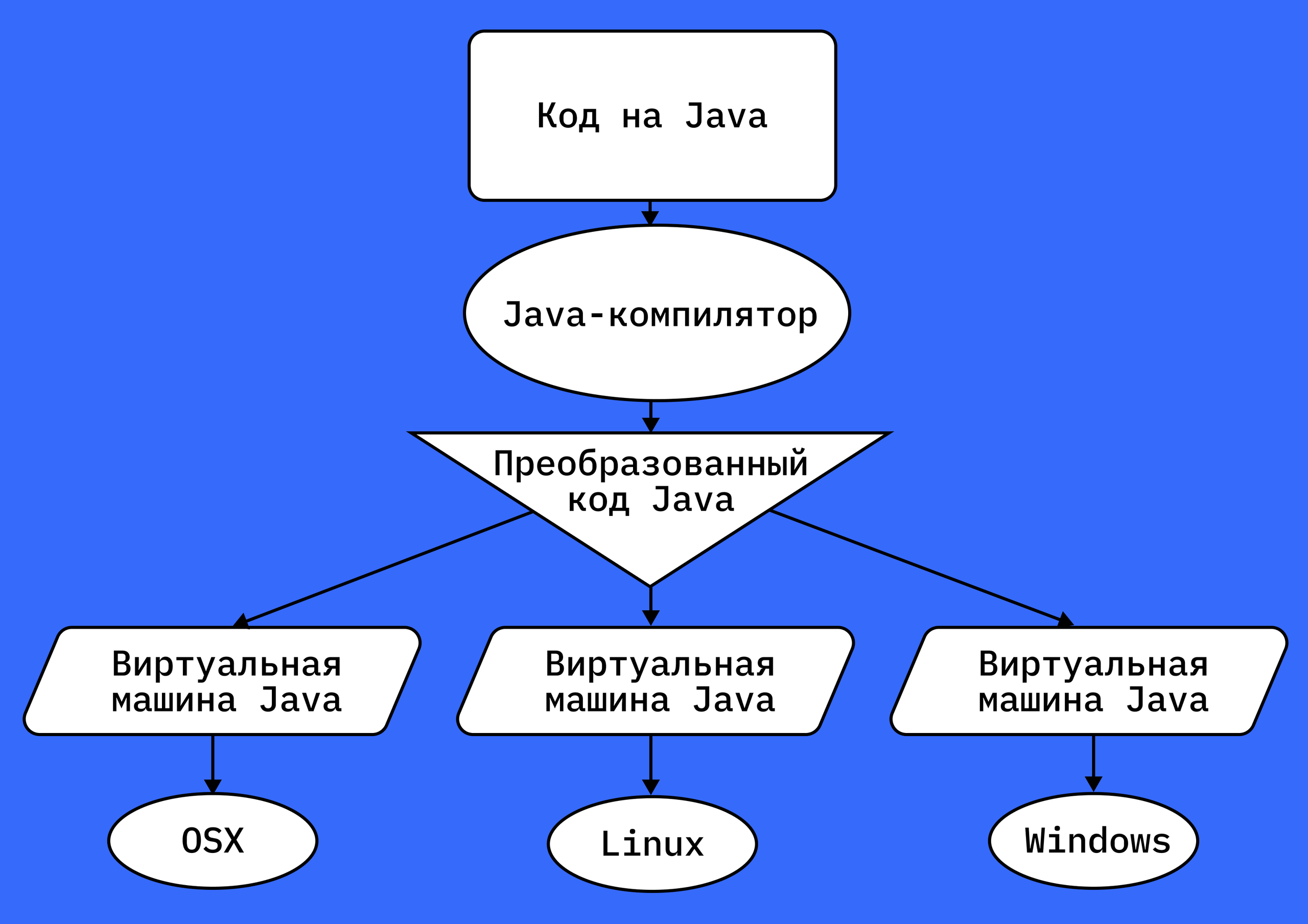
Компилятор преобразует код на Java в специальный байтовый формат, который запускается на виртуальной машине и одинаково работает на любых ОС
Именно на Java написаны многие инструменты для работы с большими данными, например почти вся экосистема Hadoop. Его используют для алгоритмов машинного обучения и разработки высокопроизводительных систем извлечения и обработки данных.
4. Scala

Не самый популярный язык — в рейтинге TIOBE он даже не в топ-20. При этом он хорошо подходит для задач по обработке данных, причём именно больших — благодаря производительности Scala пользуются крупные компании вроде Twitter, Netflix и Тинькофф.
Scala запускается на базе виртуальной машины Java, поэтому хорошо совместим с этим языком и также работает на любых устройствах. Именно на нём написан Apache Spark — важный фреймворк для анализа больших данных и машинного обучения.
5. Go

Этот язык был разработан Google специально для анализа и обработки больших данных. Ориентирован прежде всего на извлечение и анализ информации из БД, хотя также применяется для работы с искусственным интеллектом и веб-разработки.
6. MATLAB
С этим языком знакомы те, кто учился в вузе на технической специальности. Некоторые считают, что MATLAB — это программа, но на самом деле это язык для численных расчётов, разработанный ещё в прошлом веке. MATLAB предназначен для сложных математических операций и расчётов. Он больше подходит для расчёта показателей для анализа данных, а не для самого анализа.
7. Julia
Это новый язык, который разрабатывали специально для работы с данными. Его используют в машинном обучении, создании компьютерных симуляций и для написания бэкенд-части приложений.
8. C++

Это язык общего назначения: на нём пишут игры, программы и целые операционные системы. В сфере Big Data на C++ в основном пишут сами инструменты: например, MapReduce, хранилище Caffe, библиотеку нейронных сетей Minerva. Для работы с данными его используют редко, но всё же иногда применяют.
Главное о языках для работы с Big Data
- Python — самый популярный и универсальный, но работает медленнее некоторых других и может вызывать ошибки в данных из-за динамической типизации.
- R идеально подходит для комплексной аналитики и содержит тысячи готовых функций, но очень непрост в освоении и почти неприменим для других задач программирования.
- Java быстрый и ещё более универсальный, чем Python, но сложнее в освоении и имеет меньше встроенных инструментов для анализа данных.
- Scala быстро работает с большими данными, но сложен в освоении и не очень популярен.
- Go очень простой и содержит много стандартных библиотек, но пока слишком молодой и не подходит для масштабных проектов.
- MATLAB хорошо справляется с математически сложными задачами, но только с ними — для других целей он неприменим. А ещё у него платная лицензия на использование.
- Julia разработана специально для работы с данными, она быстрая и удобная. Но из-за молодости пока содержит мало готовых функций и библиотек.
- С++, скорее, язык общего назначения, и для повседневной работы аналитика данных не подходит. Но он очень быстрый, поэтому выручит там, где нужна максимальная скорость работы программы.
Подпишитесь на наш ежемесячный дайджест статей —
а мы подарим вам полезную книгу про обучение!



Читать также: