
Специалисты по Data Science тратят примерно 80% своего времени на то, чтобы подготовить данные. Рассказываем, почему это важно и из чего состоит работа по подготовке данных.

Зачем нужна подготовка данных
Исходные данные редко бывают «чистыми». Например, в них могут быть пропуски, отклонения от нормальных значений или случайные события, которые влияют на целевые показатели.

Так происходит из-за того, что чаще всего данные получают разными способами и из разных источников: собирают вручную или интегрируют из CRM-систем, хранилищ данных и открытых баз
Модель, построенная на некачественных данных, будет неточной, а результаты её работы не получится использовать. Поэтому до обучения модели нужно провести подготовку исходных данных: очистить и привести к нужному формату.
Материал по теме:
Очистка данных: кто их загрязняет и что аналитику с этим делать

Задачи предварительной обработки данных
В зависимости от качества и формата исходных данных на этапе предварительной обработки специалисты по Data Science могут решать следующие задачи:
1. Очистить данные.
При очистке данных удаляют устаревшие данные, дубликаты, аномалии, пропуски и ошибки. Но не всегда можно просто убрать все некачественные данные. Иногда их так много, что удаление повлияет на результаты машинного обучения, поэтому данные придётся редактировать.
2. Редактировать данные.
Данные могут быть записаны с ошибками или в разных форматах, поэтому их нужно корректировать. Например, в таблице может быть по-разному указано название одного и того же населённого пункта: «посёлок Заозёрный», «п. Заозёрный», «пос. Заозёрный», «поселок Заозерный». Модель будет воспринимать эти названия как разные значения, поэтому придётся привести записи к одному формату. Что касается числовых данных, то, чтобы привести их к единому формату, например, можно преобразовать значения в диапазон от 0 до 1.
3. Заполнить пропуски.
В работе с пропусками есть разные подходы. Их выбор зависит от видов и источников данных. Но сначала специалисту нужно разобраться, почему появились пропуски.
Пропуски можно заполнить наиболее вероятным значением. Например, в форме для объявления о продаже автомобиля есть графа с информацией об участии в авариях. В графе есть два варианта ответа — «да» и «нет». Специалист, который проводит подготовку данных для машинного обучения, знает, что на основе статистики эту графу чаще пропускают в случае отсутствия аварий. Поэтому он может заполнить пропуски наиболее вероятным значением — «нет».
Числовые показатели можно заменить, например, на усреднённые значения или построить алгоритм на основе взаимосвязей между показателями. С помощью такого алгоритма для каждого пропуска рассчитывается собственное значение.
4. Форматировать данные.
Инструменты машинного обучения, как правило, работают с данными в табличном формате. Поэтому набор чисел и текстовые записи преобразовывают в форматы .csv, .xls, .xlsx.
Исходные данные в виде изображений тоже преобразовывают. Их можно конвертировать в один формат или сжать до определённого размера. К изображениям могут применять чёрно-белый или другой единый цветовой фильтр и обрезать. Например, если нужна информация из конкретного поля на скане документа, которое заполняется от руки, то все сканы можно автоматически обрезать на определённое количество пикселей со всех сторон.
5. Отобрать признаки данных.
Некоторые признаки могут быть сильно связаны между собой, поэтому приводят к утечке данных. Допустим, есть два признака — год рождения и возраст. Если выгрузка данных происходит в один день, то один из этих признаков стоит удалить.
Отбор признаков также делают, чтобы снизить эффект шума. В этом случае удаляют те признаки, которые в наименьшей степени влияют на целевой показатель. Предположим, нужно сделать прогноз размера заработной платы. На этот показатель в большей степени повлияет сфера занятости и стаж работы, а вот день и месяц рождения сотрудника нет, значит, эти значения можно убрать.
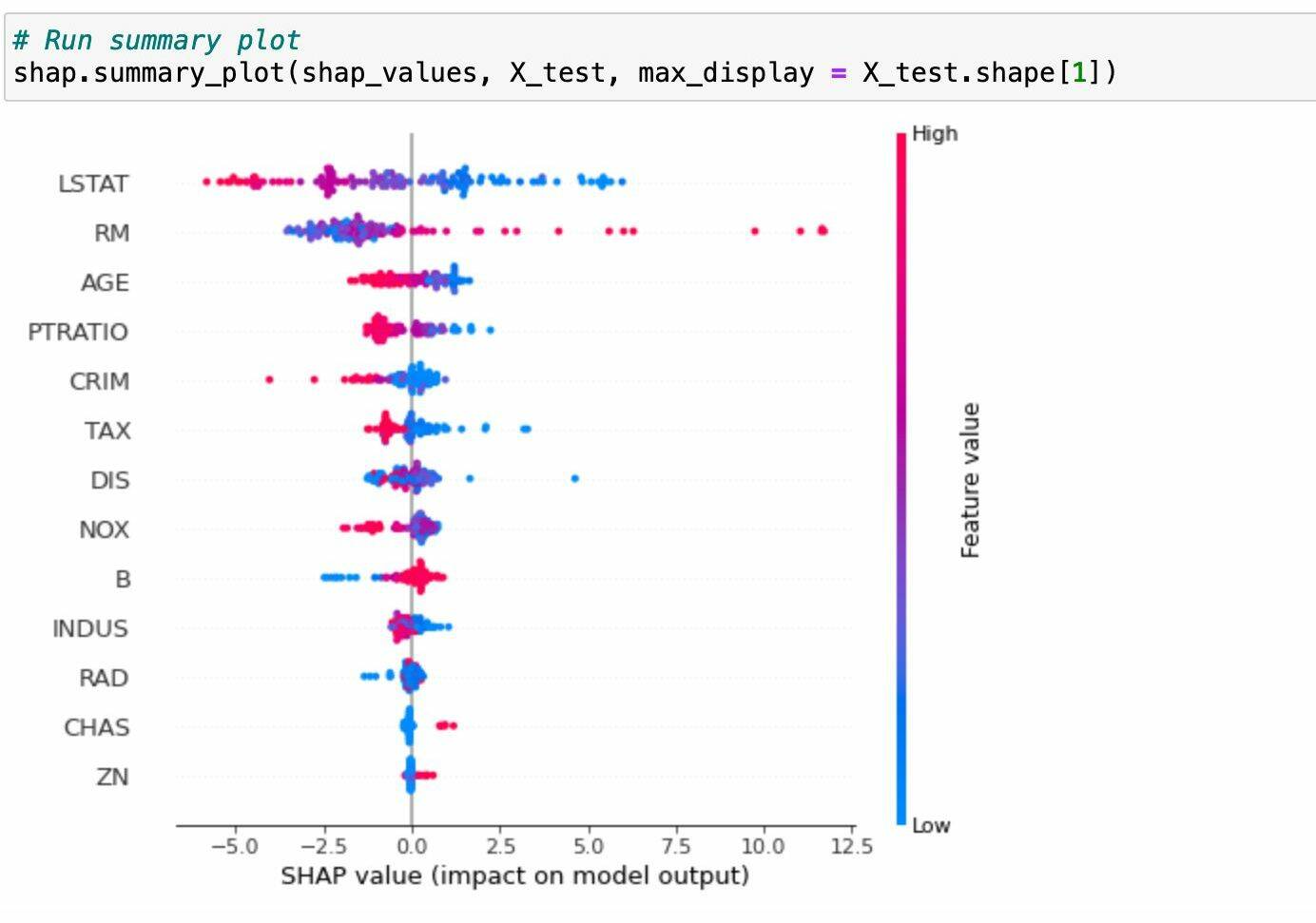
Количество признаков сокращают не только при подготовке данных, но и после обучения модели — это один из способов увеличить целевой показатель. График построен с помощью библиотеки shap в Jupyter Notebook



Методы и средства Data Preparation
Подготовка данных для машинного обучения начинается с исследовательского анализа данных. В результате выявляют параметры данных, закономерности, ошибки, аномалии и пропуски. Специалисты по Data Science проводят исследовательский анализ данных с помощью специальных инструментов и библиотек, например Jupyter Notebook, Pandas, Matplotlib и SciPy.
Дата-сайентист смотрит на результаты и принимает решение, что делать дальше. Например, анализирует объём пропусков, какие данные должны быть в них и как с этим работать — заполнять наиболее вероятными или усреднёнными значениями либо вообще написать алгоритм в Python для расчёта
На подход к подготовке данных влияют условия технического задания и доступ к внешним данным. Предположим, специалист по Data Science анализирует информацию о пиццериях города. Среди параметров есть размер среднего чека. Чтобы заполнить пропуски этого значения, можно взять среднюю цифру по конкретному району — 1 500 рублей в пиццериях центрального района. Или можно обратиться к открытым источникам данных — сайтам пиццерий, сервисам доставки, сервисам с отзывами. Тогда это значение будет разным для каждого заведения: в одной пиццерии 1 300 рублей, в другой — 1 700 рублей.
Для одних задач будет достаточно и среднего значения, для других — нужно провести дополнительную работу по сбору данных.
Основной принцип подготовки данных в том, что для принятия решений в процессе Data Preparation специалисту нужно применять собственную экспертную оценку. Поэтому кроме инструментов большую роль играет опыт специалиста. Начинающий эксперт может упустить важные моменты в процессе подготовки данных. Например, заполнить пропуски средними показателями в задаче, в которой для точности будущей модели нужно отдельно посчитать значение для каждого пропуска с помощью алгоритма.
Как преобразовать данные
Работу дата-сайентиста по подготовке и преобразованию данных можно разбить на этапы:
1. Выгрузка данных и преобразование в нужный формат.
Все данные для анализа переводят в табличный формат, который можно загрузить в Pandas или другой инструмент для подготовки данных. В табличном формате все показатели разносят по разным колонкам.
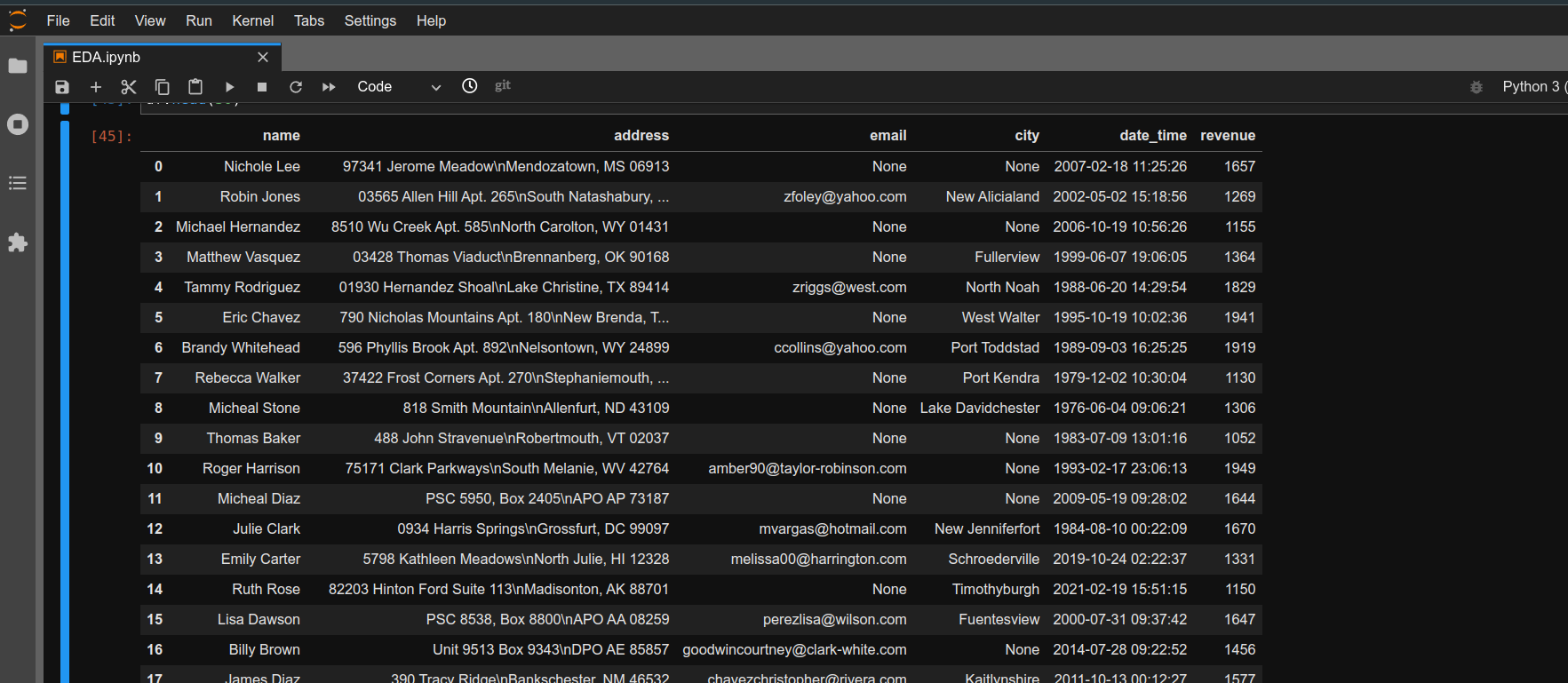
Таблица с данными с сайта покупок в формате .ipynb, которую можно открыть в Jupyter Notebook
2. Исследовательский анализ данных.
С помощью инструментов и вручную специалист анализирует состав и качество данных: какие есть показатели, как они связаны между собой, как влияют на целевой показатель, какие есть аномалии, какой объём пропусков.
С помощью инструментов и вручную специалист анализирует состав и качество данных: какие есть показатели, как они связаны между собой, как влияют на целевой показатель, какие есть аномалии, какой объём пропусков.
3. Работа с каждой колонкой по отдельности.
Специалист сам принимает решение, что делать с данными в каждой конкретной колонке: какой подход выбрать для заполнения пропусков и какие показатели убрать из таблицы. Решение зависит от результатов исследовательского анализа, целей машинного обучения, ресурсов, которые есть у специалиста.
Бывает, что данные, которые нужно подготовить, оказываются настолько некачественными, что их невозможно преобразовать и использовать в аналитике и задачах машинного обучения. Например, могут быть собраны данные, которые не отображают бизнес-процессы, или сбор данных был неправильно организован. Если сотрудники компании собирали данные вручную, не имея нужных навыков, в них может быть много ошибок и некорректных значений.
В таких ситуациях нужно сообщить заказчику о проблеме и собрать данные заново. Тогда к подготовке данных добавляется ещё один этап — их сбор.
Совет эксперта
Ян Анисимов
Подготовка данных — это кропотливый процесс, на который уходит большая часть времени специалиста по Data Scienсе. Но это важнейшая часть работы, от которой зависит точность и эффективность обучаемых моделей. Именно во время подготовки данных могут появляться идеи для решения бизнес-задач и гипотезы для машинного обучения.
Дайджест блога: ежемесячная подборка лучших статей от редакции


Читать также:



