Аналитикам часто приходится иметь дело с неструктурированными данными разных форматов, которые не загрузишь в обычную базу. На помощь приходит озеро данных, или Data Lake.

Что такое Data Lake
Представим компанию, у которой много данных из разных источников: сайта интернет-магазина, кассовых аппаратов, опросов клиентов, CRM-систем, записей камер в торговом зале. Все эти данные нужно где-то хранить, чтобы использовать для анализа.
Простая база данных для этого будет не лучшим выбором по двум причинам:
● Она не предназначена для работы с большими объёмами данных, поступающими регулярно. База с ростом нагрузки начнет медленнее читать и записывать информацию, а также не сможет равномерно расширяться, или автомасштабироваться, если данных станет слишком много.
● Часто база нужна для нормальной работы основных систем бизнеса, например, сайта. Если обращаться к ней ещё и за аналитикой, она может перегрузиться, из-за чего сайт начнёт тормозить или сломается. Поэтому базу для бизнеса и для аналитики нужно разделять.
Для этого есть два варианта решения: хранилище данных и озеро данных. Хранилище — это по сути та же база, в которую можно складывать структурированную информацию. Данные в нём хранятся в таблицах, и перед загрузкой их нужно обработать и структурировать.
Разрозненные, неструктурированные данные разных форматов разместить в хранилище не получится. Чтобы решить эту проблему, придумали Data Lake, в переводе с английского «озеро данных». Это инструмент, который позволяет хранить любые данные: csv, xml, json, parquet, jpg, png, mov, mp3, pdf и другие. В него можно загружать таблицы, у которых нет чёткой структуры, то есть периодически меняется количество и названия колонок и строк. Все эти данные можно загружать в озеро без обработки, то есть практически мгновенно.

Вот некоторые виды данных, которые можно хранить в озере. Их формат, структура и объём не важны
Материал по теме:
Для чего начинающим аналитикам нужны деревья решений

Кому и зачем нужны озёра данных
Озёра данных предназначены для того, чтобы собирать, хранить и обрабатывать большое количество информации, поступающей практически непрерывным потоком. Такую информацию называют Big Data, или большими данными.
Data Lake полезны всем компаниям, которые планируют анализировать большие данные любой области, например ретейла, IT, промышленности или логистики.
Само по себе озеро данных бесполезно, потому что это просто хранилище. Чтобы с ним работать, нужны инструменты для очистки, структурирования, извлечения и анализа данных, и специалисты для работы с этими инструментами.




Без Data Lake можно обойтись, если компания:
● Вообще не работает с Big Data и не планирует делать это в ближайшем будущем. Обычно это характерно для небольшого бизнеса с минимальной IT-инфраструктурой и небольшим объёмом поступающих данных.
● В основном собирает структурированные данные, например, из баз или систем сбора метрик. В таком случае их сразу можно помещать в хранилища и использовать для аналитики.
Как устроено озеро данных
Озеро представляет собой файловое хранилище на нескольких серверах, в котором лежат данные. Как правило данные распределены между серверами, чтобы хранилище можно было быстро масштабировать — подключить новые серверы для расширения места.
К серверам настраивают подключение разных источников данных, доступных компании. Каналы поставки данных называют пайплайнами, а всю схему подключения — ETL-процессом. Обычно всё настроено так, чтобы данные загружались автоматически.
Хотя Data Lake и неструктурированное, порядок в нём всё-таки должен быть, иначе спустя время накопится огромное количество данных, в которых невозможно будет разобраться. Поэтому перед добавлением в озеро данные размечают и запоминают, откуда и в каком формате они поступили.
В итоге внутри озера данных хранятся не только сами объекты, но и метаданные, то есть информация об объектах. Это облегчает поиск, извлечение и анализ данных в будущем.
В архитектуре озера данных должны быть предусмотрены инструменты резервного копирования, чтобы информация не терялась.
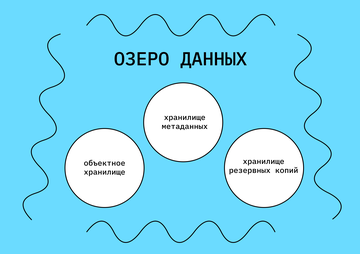
Внутри озера данных схема хранения может быть такой. Но это не обязательно — каждый организует свое озеро сам, в зависимости от потребностей бизнеса
Озеро данных не существует само по себе. К нему примыкают другие инструменты:
● Источники, в которых данные генерируются и собираются. Это могут быть базы данных, CRM, ERP, IoT и другие системы и сервисы.
● Аналитические сервисы, которые отбирают, сортируют и анализируют информацию. Например, это BI-инструменты для построения дашбордов. Или сервисы машинного обучения для создания ML-моделей и нейросетей.
● Хранилища, в которых лежат уже структурированные и очищенные данные из озера.
Аналитики данных взаимодействуют именно с инструментами, а не с Data Lake напрямую. Современные озёра данных, как правило, строят с помощью инструмента Hadoop. Он позволяет хранить поступающую информацию на разных подсерверах и обрабатывает её параллельно, что значительно ускоряет работу.

Схематично структура хранения выглядит так. При загрузке файлы равномерно распределяются по разным серверам, и затем запрос на выгрузку обрабатывается на каждом сервере параллельно. Это позволяет выполнить его в несколько раз быстрее, чем если бы все данные выгружались с одного сервера
Как работают Data Lake
- В одном из источников формируются данные. Например, в социальной сети пользователи отправляют друг другу сообщения с текстом, картинками, видео и голосовыми.
- По заранее настроенному маршруту данные с серверов соцсети отправляются в Data Lake.
- При поступлении данные размечаются: записывается их источник, время поступления, формат и структура.
- Данные помещаются в озеро и хранятся там. Как правило, срок хранения не ограничен, хотя иногда данные удаляют по мере устаревания или использования в аналитике.
- При необходимости данные извлекают из хранилища по определённым критериям и используют в аналитике и машинном обучении.
Озёра данных и хранилища данных
Для работы с большими объёмами данных используют Data Warehouse и Data Lake. Разберем, в чём отличия понятий хранилище и озера данных.
Озеро данных, Data Lake.
Предназначены для хранения данных любых типов. Перед аналитикой их нужно обязательно найти, очистить и структурировать, то есть поместить в озеро просто, а извлекать — сложнее. Из-за отсутствия структуры и простого обслуживания озеро данных обходится дешевле, чем хранилище.
Хранилище данных, Data Warehouse.
Построено на основе распределённых баз данных — как классических, так и специальных, типа ClickHouse. Оно содержит уже отсортированную, преобразованную и структурированную информацию. Данные из хранилища можно сразу использовать в анализе. Помещать информацию в хранилище занимает больше времени, потому что её нужно предварительно структурировать. Из-за структуры данные в хранилище занимают больше места и требуют более сложного обслуживания, поэтому само хранилище обходится дороже, чем озеро данных.
Существуют гибридные хранилища, в которых сначала все неструктурированные данные помещают в озеро, а затем берут их оттуда, очищают, структурируют и загружают в хранилище.
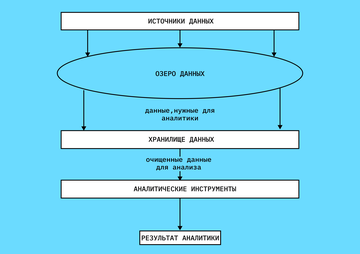
Так выглядит движение данных в гибридном хранилище, которое совмещает в себе озеро и хранилище структурированной информации
Недостатки озёр данных
Потеря качества данных. Озеро имеет склонность становиться «болотом» — накапливать данные, которые плохо размечены и никому не нужны. Это может привести к тому, что Data Lake просто больше нельзя будет использовать для аналитики — его придется полностью стирать и наполнять заново, уже более аккуратно.
Техническая сложность. Создание озера данных — непростая задача. Нужна инфраструктура: мощные серверы, надёжные каналы связи, большие объёмы дискового пространства, а ещё опытные инженеры, которые будут это поддерживать. Технология Data Lake для России относительно новая, и специалистов на рынке не очень много, поэтому их придётся долго искать и много им платить.
Дополнительные затраты на извлечение данных. Помещать данные в озеро можно почти мгновенно, а для извлечения часто нужны сложные инструменты поиска и очистки, которые придётся настраивать отдельно. В этом плане озеро уступает хранилищу данных, в котором всё хранится по заранее проработанной структуре.
Хранение лишнего. Данные в озеро часто поступают бесконтрольно. Из-за этого в нём может быть много дублей и файлов, которые вообще не нужны ни для какой аналитики. Из-за этого озеро может разрастись и потреблять слишком много ресурсов бизнеса.
Совет эксперта
Александр Толмачёв
Data Lake — это достаточно надёжный и дешёвый способ хранения данных. Чтобы с ним работать, в компании нужно развивать контроль качества, процессы поставки и политику управления данными. Это называется культурой работы с данными, и без неё озеро не принесёт пользы. Поэтому работать над строительством и наполнением Data Lake нужно комплексно, в сотрудничестве с разными специалистами и с использованием современных подходов и технологий.
Дайджест блога: ежемесячная подборка лучших статей от редакции


Читать также:



